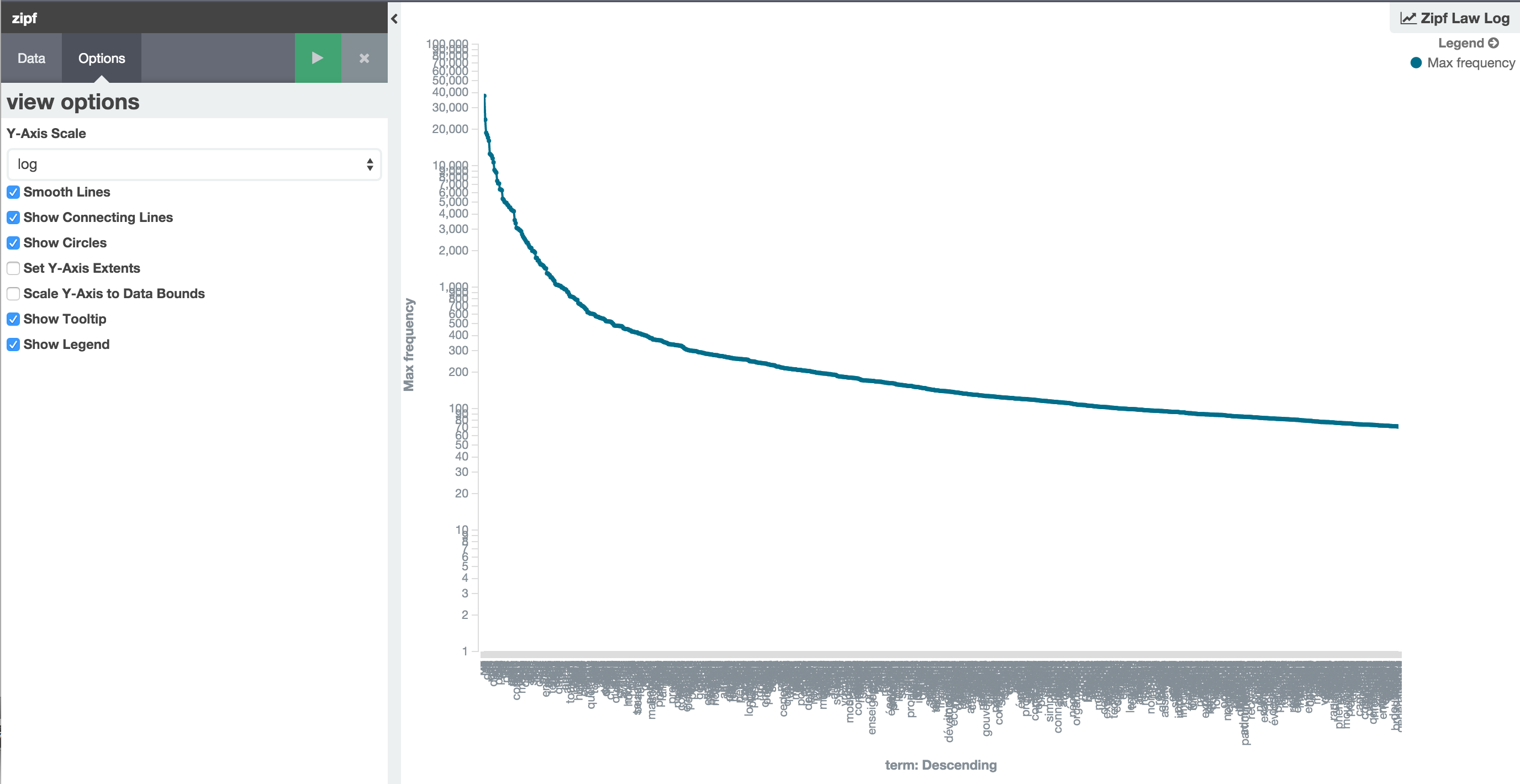
I just discovered a nice video which explains the Zipf’s law.
I’m wondering if I can index the french lexique from Université de Savoie and find some funny things based on that…
Download french words wget http://www.lexique.org/listes/liste_mots.txt head -20 liste_mots.txt What do we have?
It’s a CSV file (tabulation as separator):
1_graph 8_frantfreqparm 0 279.84 1 612.10 2 1043.90 3 839.32 4 832.23 5 913.87 6 603.42 7 600.61 8 908.03 9 1427.45 a 4294.90 aa 0.
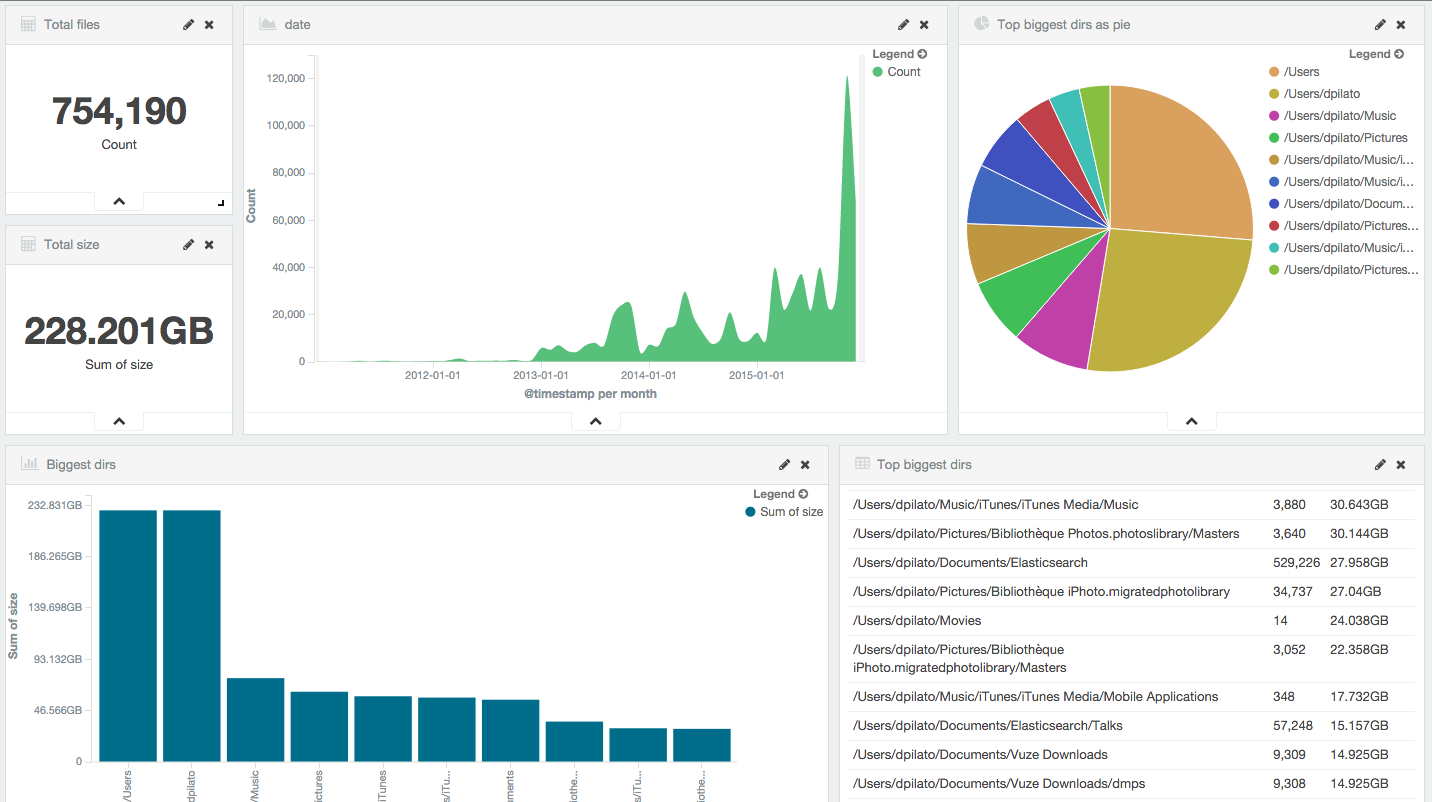
I gave a BBL talk recently and while chatting with attendees, one of them told me a simple use case he covered with elasticsearch: indexing metadata files on a NAS with a simple ls -lR like command. His need is to be able to search on a NAS for files when a user wants to restore a deleted file.
As you can imagine a search engine is super helpful when you have hundreds of millions files!
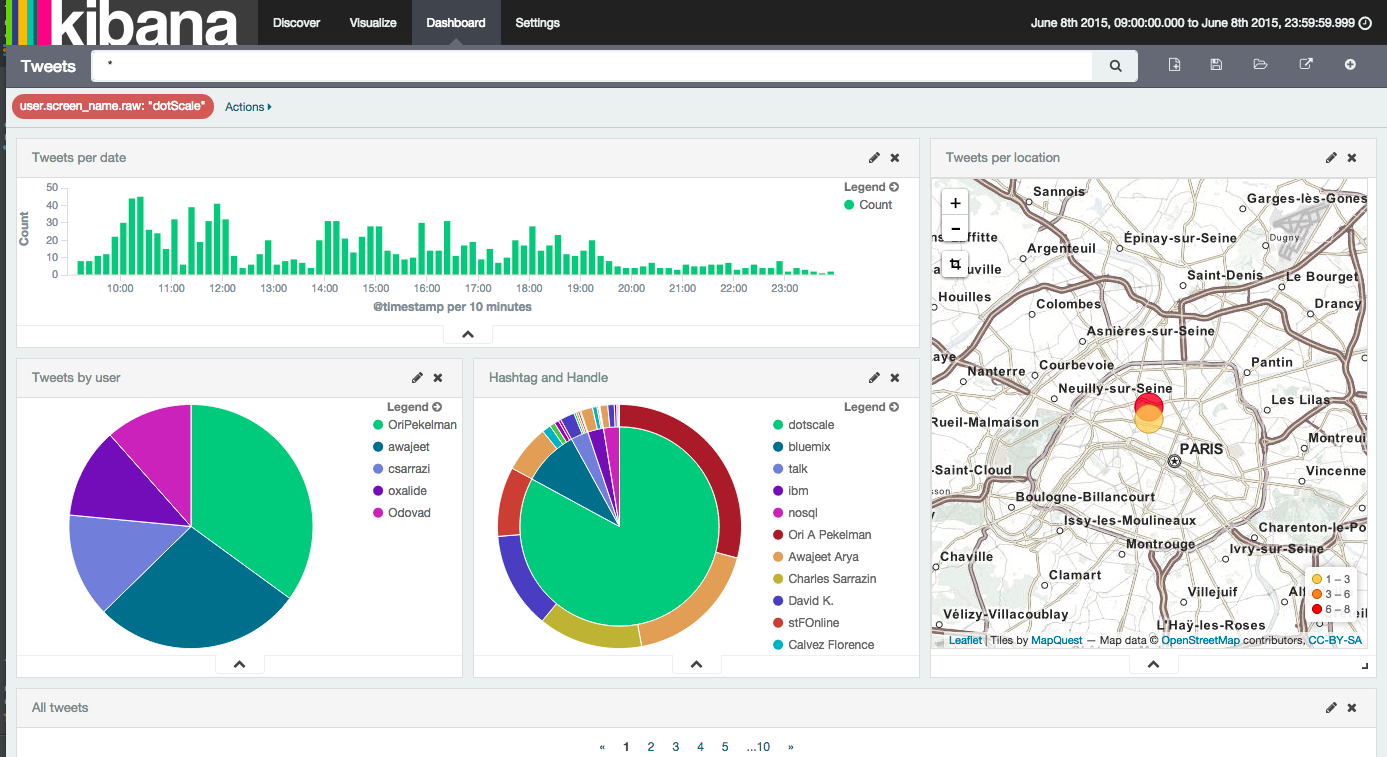
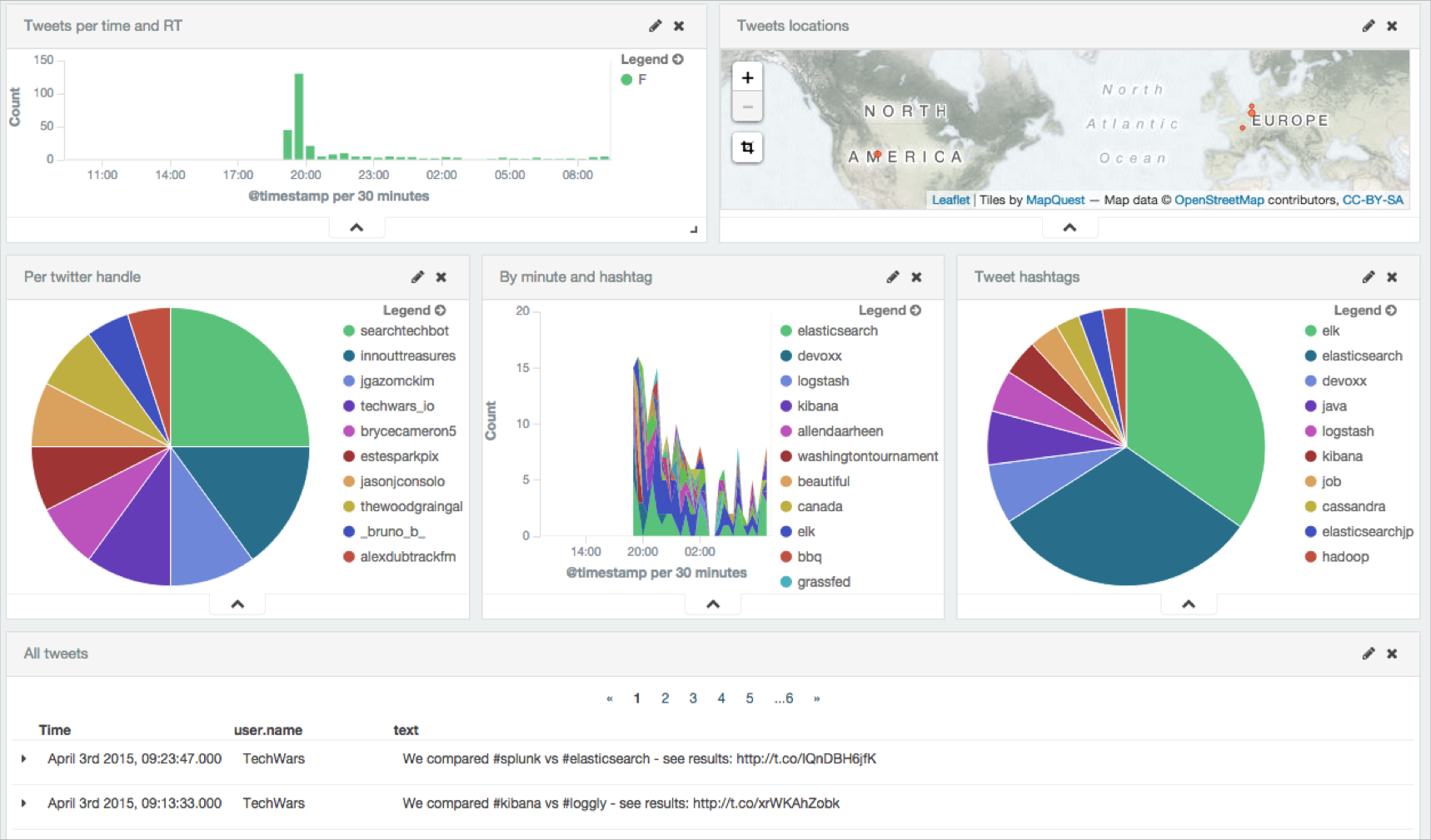
Some months ago, I published a recipe on how to index Twitter with Logstash and Elasticsearch.
I have the same need today as I want to monitor Twitter when we run the elastic FR meetup (join us by the way if you are in France!).
Well, this recipe can be really simplified and actually I don’t want to waste my time anymore on building and managing elasticsearch and Kibana clusters anymore.
Let’s use a Found by elastic cluster instead.
This article is based on Recommender System with Mahout and Elasticsearch tutorial created by MapR.
It now uses the 20M MovieLens dataset which contains: 20 million ratings and 465 000 tag applications applied to 27 000 movies by 138 000 users and was released in 4/2015. The format with this recent version has changed a bit so I needed to adapt the existing scripts to the new format.
Prerequisites Download the 20M MovieLens dataset. Unzip it.
Recently, I got a database MySQL dump and I was thinking of importing it into elasticsearch.
The first idea which pops up was:
install MySQL import the database read the database with Logstash and import into elasticsearch drop the database uninstall MySQL Well. I found that some of the steps are really not needed.
I can actually use ELK stack and create a simple recipe which can be used to import SQL dump scripts without needing to actually load the data to a database and then read it again from the database.
I’m often running some demos during conferences where we have a booth. As many others, I’m using Twitter feed as my datasource.
I have been using Twitter river plugin for many years but, you know, rivers have been deprecated.
Logstash 1.5.0 provides a safer and more flexible way to deal with tweets with its twitter input.
Let’s do it!
Let’s assume that you have already elasticsearch 1.5.2, Logstash 1.5.0 and Kibana 4.0.2 running on your laptop or on a cloud instance.
Sometimes, you would like to reindex your data to change your mapping or to change your index settings or to move from one server to another or to one cluster to another (think about multiple data centers for example).
For the later you can use Snapshot and Restore feature but if you need to change any index settings, you need something else.
With Logstash 1.5.0, you can now do it super easily using elasticsearch input and elasticsearch output.
Using Found by elastic cluster helps a lot to have a ready to use and managed elasticsearch cluster.
I started my own cluster yesterday to power brownbaglunch.fr website (work in progress) and it was ready to use after some clicks!
It’s a kind of magic!
But I ran into an issue when you secure it and use the elasticsearch javascript client.
Creating your cluster Found Console
Adding ACL By default, your cluster is opened but you can fix that by opening “Access Control” menu.
I gave recently a talk at Voxxed Istanbul 2015 and I’d like to share here the story of this talk.
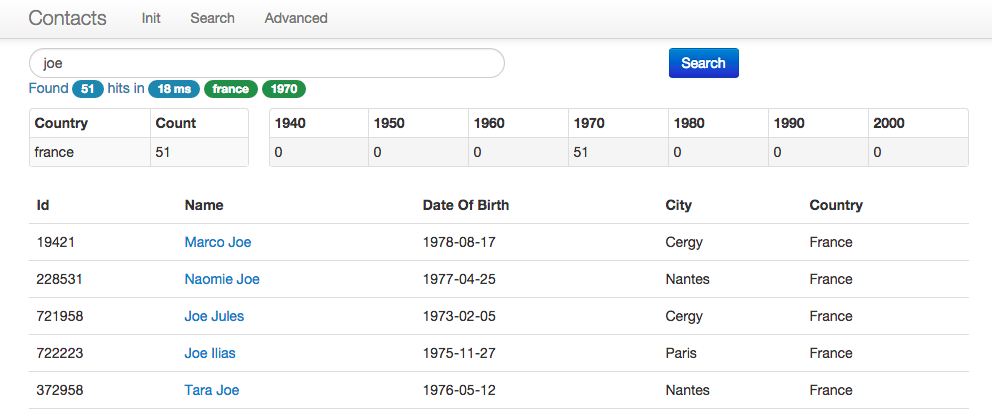
The talk was about adding a real search engine for your legacy application. Here “legacy” means an application which is still using SQL statements to execute search requests.
Our current CRM application can visualize our customers. Each person is represented as a Person bean and have some properties like name, dateOfBirth, children, country, city and some metrics related to the number of clicks each person did on the car or food buttons on our mobile application (center of interests that is).
I gave recently a talk at Devoxx France 2015 with Colin Surprenant and I’d like to share here some of the examples we used for the talk.
The talk was about “what my data look like?”.
We said that our manager was asking us to answer some questions:
who are our customers? how do they use our services? what do they think about us on Twitter? Our CRM database So we have a PostgreSQL database containing our data.
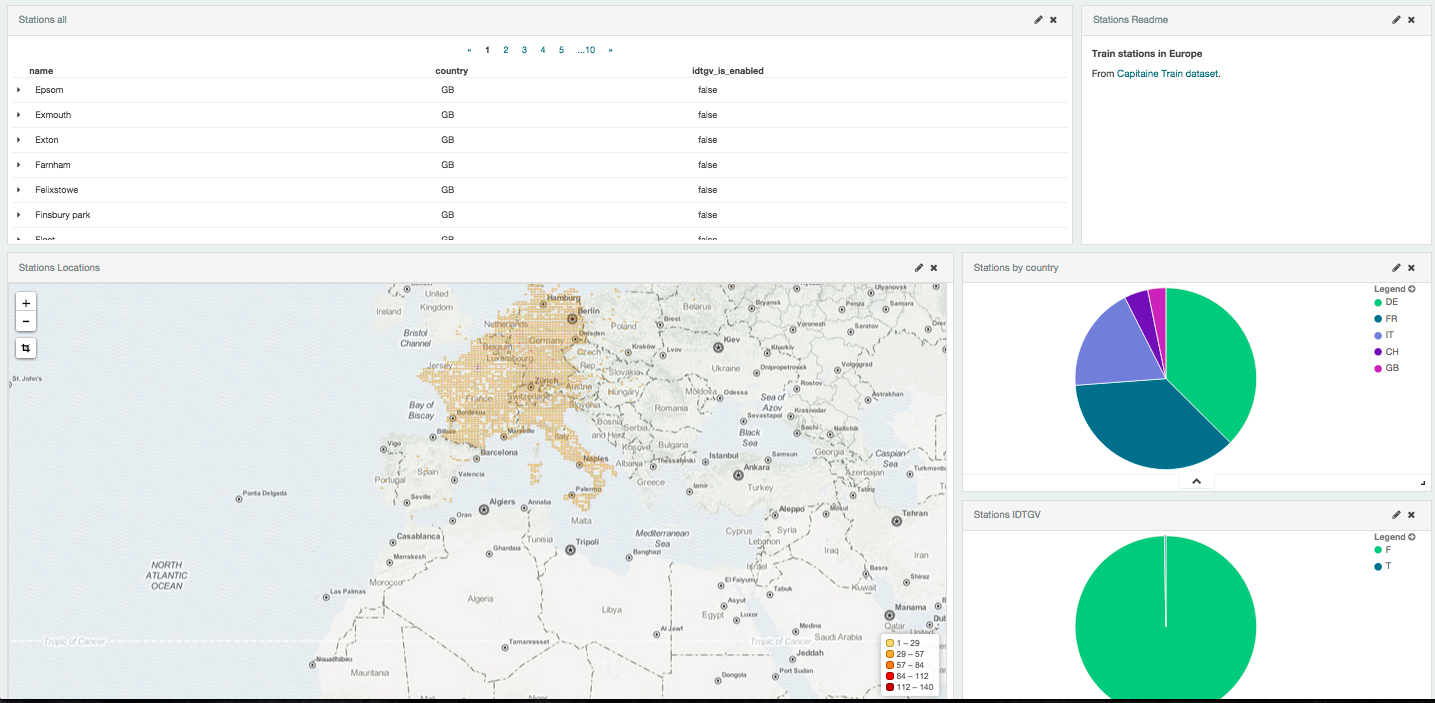
Recently I saw a tweet where Capitaine Train team started to open data they have collected and enriched or corrected.
Ouvrez, ouvrez, les données structurées. Capitaine Train libère les gares : https://t.co/y6DjWsbALF #opendata
— Trainline France (@trainline_fr) April 23, 2015 I decided to play a bit with ELK stack and create a simple recipe which can be used with any other CSV like data.
Prerequisites You will need:
Logstash: I’m using 1.5.0-rc3. Elasticsearch: I’m using 1.
I was trying to use Hibernate 4.3.8.Final with Log4J2 and I spent some hours to find why Hibernate was not using Log4J2 though it was declared in my pom.xml file.
Actually, I hit issue JBLOGGING-107.
The workaround is simply to add a more recent jboss-logging dependency than the one shipped by default with Hibernate 4.3.8.Final.
<dependency> <groupId>org.jboss.logging</groupId> <artifactId>jboss-logging</artifactId> <version>3.2.1.Final</version> </dependency>
Oh wait! Already 2 years spent working for Elasticsearch? Time flies!
After the first year, I wrote that I did 58 talks in 4 countries, 37 towns for about 18 000 kilometers traveled. I was pretty sure that things would continue to grow.
This year, I spoke 78 times! Around 2 talks per week! I did around 48 000 kilometers. 8 000 km more than the earth’s circumference! I still can’t believe it… 12 countries. And no need to say that I love giving talks and sharing my enthusiasm about Elasticsearch!
I joined Elasticsearch Inc one year ago. Those were pretty exciting days!
But now…
It’s more than that! Really! You could think that after one year, my motivation would start to decrease. I have the total opposite feeling. Still excited by my job, by the company and by the project, but most of all by the amazing team I’m lucky to work with! Everyone is different and each of us adds different value to Elasticsearch. Personally, I learn a lot from my co-workers.
Once upon a time…
In fact 2 years ago, I was looking for a way to make Hibernate search distributed on multiple nodes. My first idea was to store indexes in a single database shared by my nodes. Yes, it’s a stupid idea in term of performances but I would like to try to build it.
Digging for source code, I came to the JdbcDirectory class from the compass project. And I saw on the compass front page something talking about the future of Compass and Elasticsearch.
Il était une fois…
En fait, il y a 2 ans, je cherchais un moyen pour distribuer Hibernate search sur plusieurs noeuds. Ma première idée était de stocker les index dans une base de données partagée par les différents noeuds. Oui ! Il s’agit d’une idée stupide en terme de performances, mais j’avais envie d’essayer et de construire ce modèle.
Après avoir cherché du code source, je suis finalement tombé sur la classe JdbcDirectory du projet Compass.
Avec Malloum, nous venons de publier notre premier projet open-source commun: Scrut My Docs !
Technical overview
Nos objectifs Fournir une application web clé en main permettant d’indexer des documents de vos disques locaux. Fournir à la communauté Elasticsearch un modèle de base pour développer votre propre webapp pour une utilisation simple de recherche (« à la google »). Aider les débutants Elasticsearch Java avec des exemples concrets en Java Les technologies employées Elasticsearch ! et son écosystème (rivers, plugins) Spring JSF Primefaces Comment démarrer ?
Et voilà, la première release de la factory spring vient d’être faite.
Vous pouvez donc maintenant l’utiliser dans vos projets Maven :
<dependency> <groupId>fr.pilato.spring</groupId> <artifactId>spring-elasticsearch</artifactId> <version>0.0.1</version> </dependency> Le code source est disponible sur github.
Nativement, Elasticsearch expose l’ensemble de ses services sans aucune authentification et donc une commande du type curl -XDELETE http://localhost:9200/myindex peut faire de nombreux dégâts non désirés.
De plus, si vous développez une application JQuery avec un accès direct depuis le poste client à votre cluster Elasticsearch, le risque qu’un utilisateur joue un peu avec votre cluster est grand !
Alors, pas de panique… La société Sonian Inc. a open sourcé son plugin Jetty pour Elasticsearch pour notre plus grand bonheur 😉
Le besoin Il existe dans Hibernate une fonctionnalité que j’aime beaucoup : la mise à jour automatique du schéma de la base en fonction des entités manipulées.
Mon besoin est de faire quasiment la même chose avec Elasticsearch. C’est à dire que je souhaite pouvoir appliquer un mapping pour un type donné à chaque fois que je démarre mon projet (en l’occurrence une webapp).
En me basant sur le projet développé par Erez Mazor, j’ai donc développé unefactory Spring visant à démarrer des clients (voire des noeuds) Elasticsearch.